Technical Notes
Study
시뮬레이션, 강화학습, 로봇 제어, 개발 환경 구축 과정 정리 노트입니다
![[SO-ARM 101 Manipulator Project Part 3] 2-CAM 환경 구축, Test Workspace 세팅, 데이터 수집과 Policy에 대한 고민](/study-media/so-arm-101-manipulator-project-part-3-2-cam-test-workspace-policy/2026-07-04-1-23-47.png)
[SO-ARM 101 Manipulator Project Part 3] 2-CAM 환경 구축, Test Workspace 세팅, 데이터 수집과 Policy에 대한 고민
Wrist CAM과 Overview CAM을 함께 사용하는 2-camera dataset을 구축하고, ACT와 Diffusion Policy를 동일 조건에서 학습한 뒤 Test Workspace 기반 평가 구조를 정리
Read post![[SO-ARM 101 Manipulator Project Part 2] 학습 데이터 수집, Behavior Cloning 1차 테스트](/study-media/so-arm-101-manipulator-part-2/so2thumb.png)
[SO-ARM 101 Manipulator Project Part 2] 학습 데이터 수집, Behavior Cloning 1차 테스트
SO-ARM101으로 100개 시연을 수집하고 97 episode·72,643 frame의 clean dataset을 만든 뒤, ACT를 20,000 step 학습해 실제 Pick-and-Place를 실행한 첫 행동복제 실험
Read post![[SO-ARM 101 Manipulator Project Part 1] 로봇 조립, Calibration, Teleoperation](/study-media/so-arm-101-part-1/video-04-poster.jpg)
[SO-ARM 101 Manipulator Project Part 1] 로봇 조립, Calibration, Teleoperation
SO-ARM 101 리더·팔로워 암의 조립, 모터 ID 설정, 캘리브레이션, 텔레오퍼레이션 검증 기록
Read post
토크-열 피드백 보상 설계를 통한 강화학습 기반 사족보행 안정성 향상
Unitree Go2 기반 MuJoCo 사족보행 실험에서 Thermal에만 패널티를 준 정책과 Thermal+Torque에 함께 패널티를 준 정책의 열 안정성과 직진성을 비교하여 적절한 보상함수 설계의 필요성을 확인한 프로젝트
Read post![[Isaac Lab Part 5] Mimic과 Robomimic으로 Franka Cube Stacking BC 학습하기](/study-media/isaaclab-bc-franka/franka-stack-official.jpg)
[Isaac Lab Part 5] Mimic과 Robomimic으로 Franka Cube Stacking BC 학습하기
Isaac Lab 공식 Franka cube stacking demonstration을 사용해 Mimic annotation, 추가 demonstration 생성, Robomimic BC-RNN 학습, checkpoint 확인까지 이어지는 흐름을 정리한다.
Read post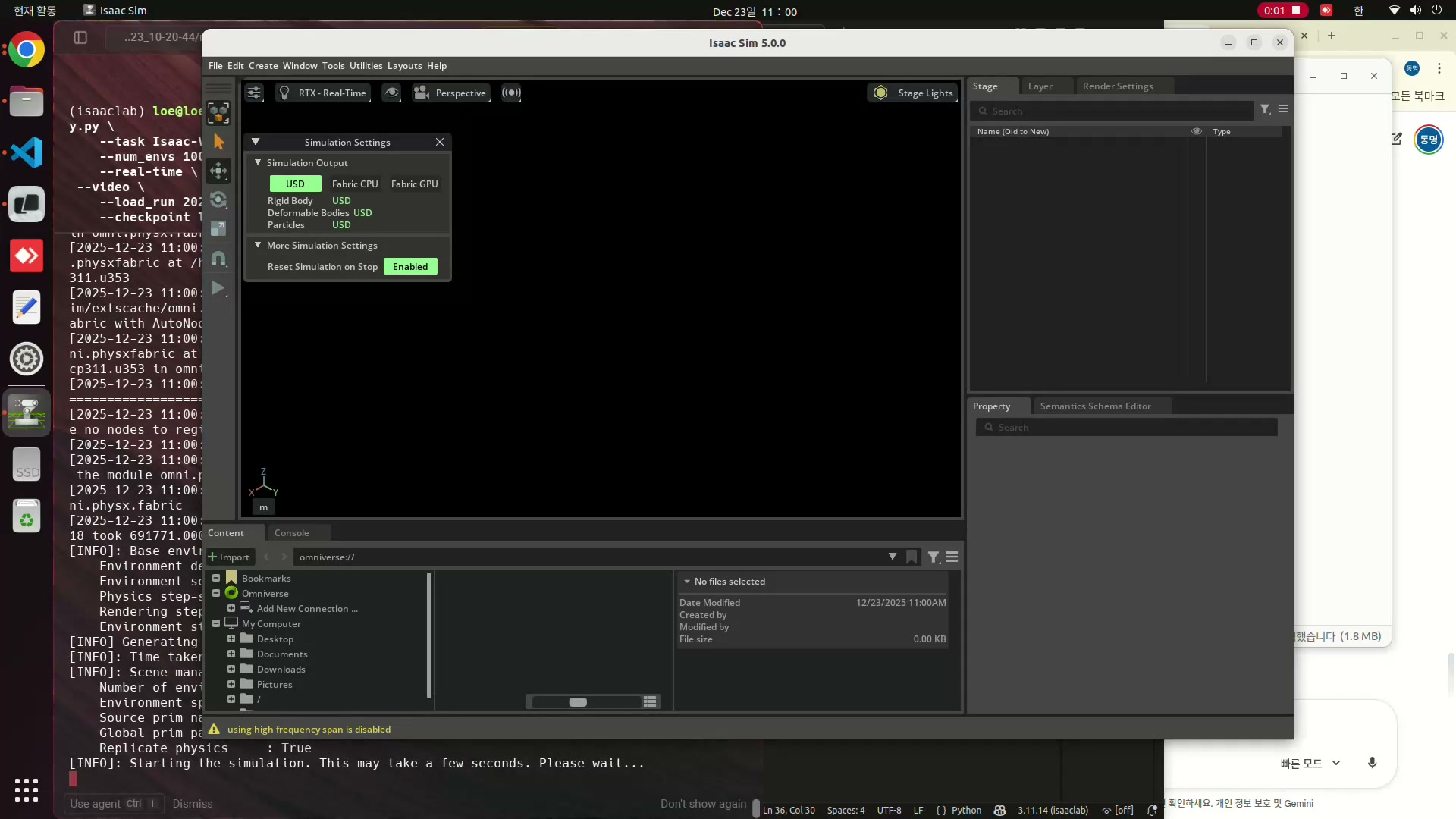
[Isaac Lab Part 4] 학습된 RL Policy를 Isaac Sim에서 실행하기
RSL-RL로 학습한 Unitree Go2 보행 policy를 Isaac Sim 추론 환경에 연결하는 과정을 정리한다.
Read post
[Isaac Lab Part 3] RSL-RL로 Unitree Go2 보행 Policy 학습하기
Isaac Lab manager-based 환경과 RSL-RL PPO runner가 Go2 보행 학습을 구성하는 흐름을 정리한다.
Read post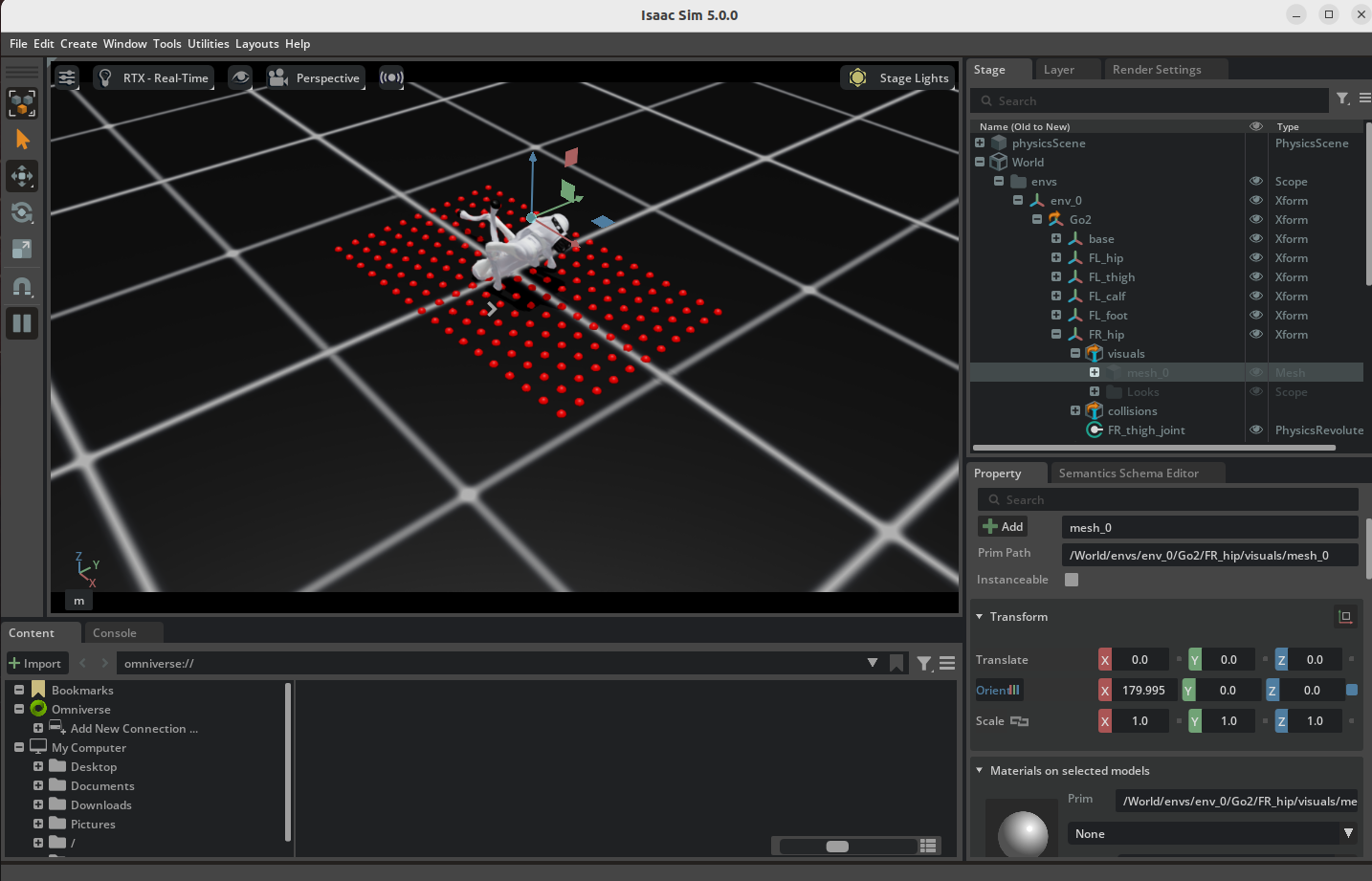
[Isaac Lab Part 2] Unitree Go2 보행 환경 구성하기
InteractiveSceneCfg와 SimulationContext로 Unitree Go2, terrain, height scanner를 포함한 scene을 구성한다.
Read post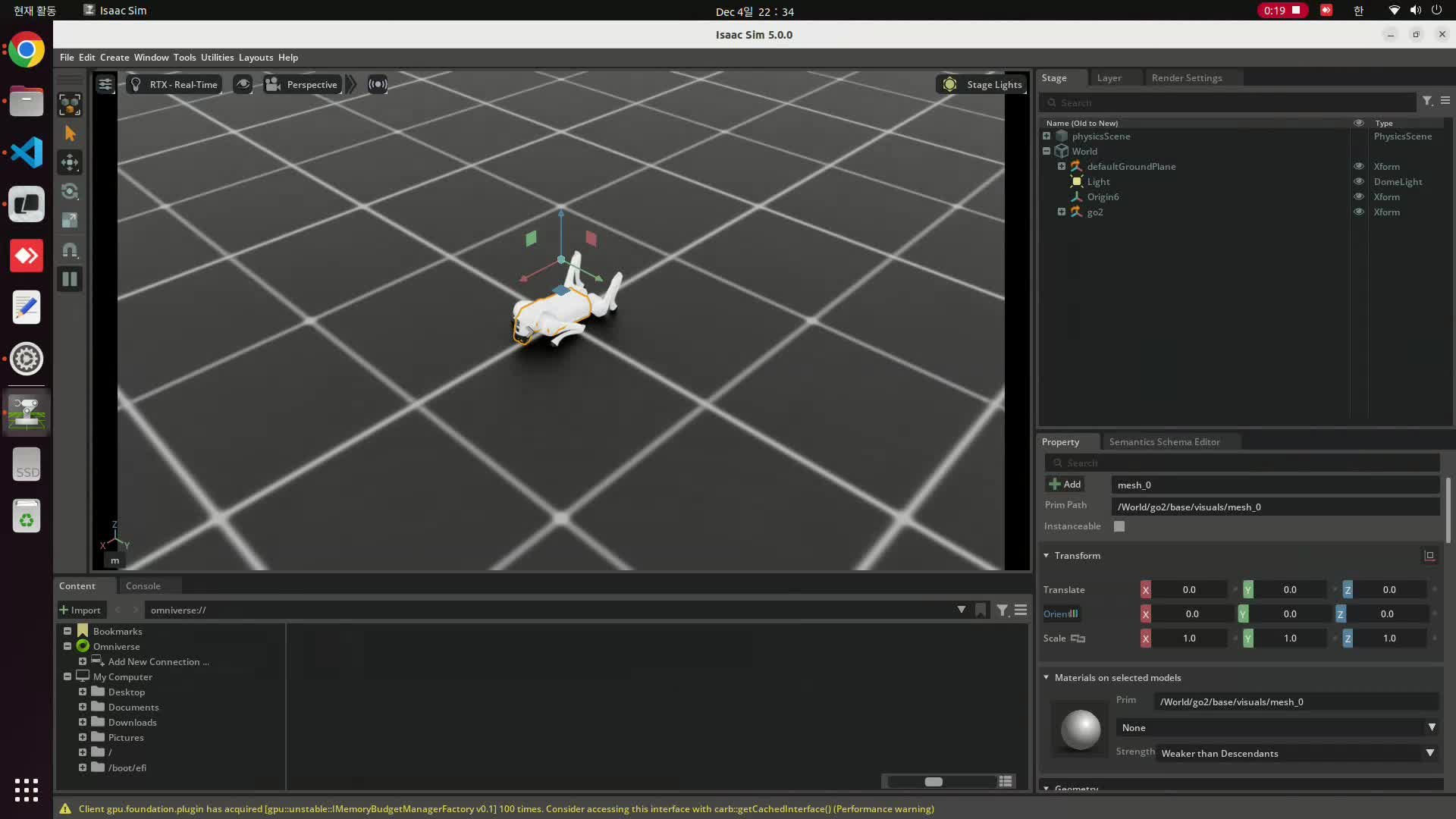
[Isaac Lab Part 1] Unitree Go2 URDF 불러오기
Isaac Lab asset config와 custom script를 이용해 Unitree Go2를 Isaac Sim scene에 배치하는 과정을 정리한다.
Read post
Isaac Sim ROS2 Tutorial 6: Franka Joint Control
Franka Panda의 joint state를 ROS2로 publish하고 joint command를 subscribe해 articulation을 제어한다.
Read post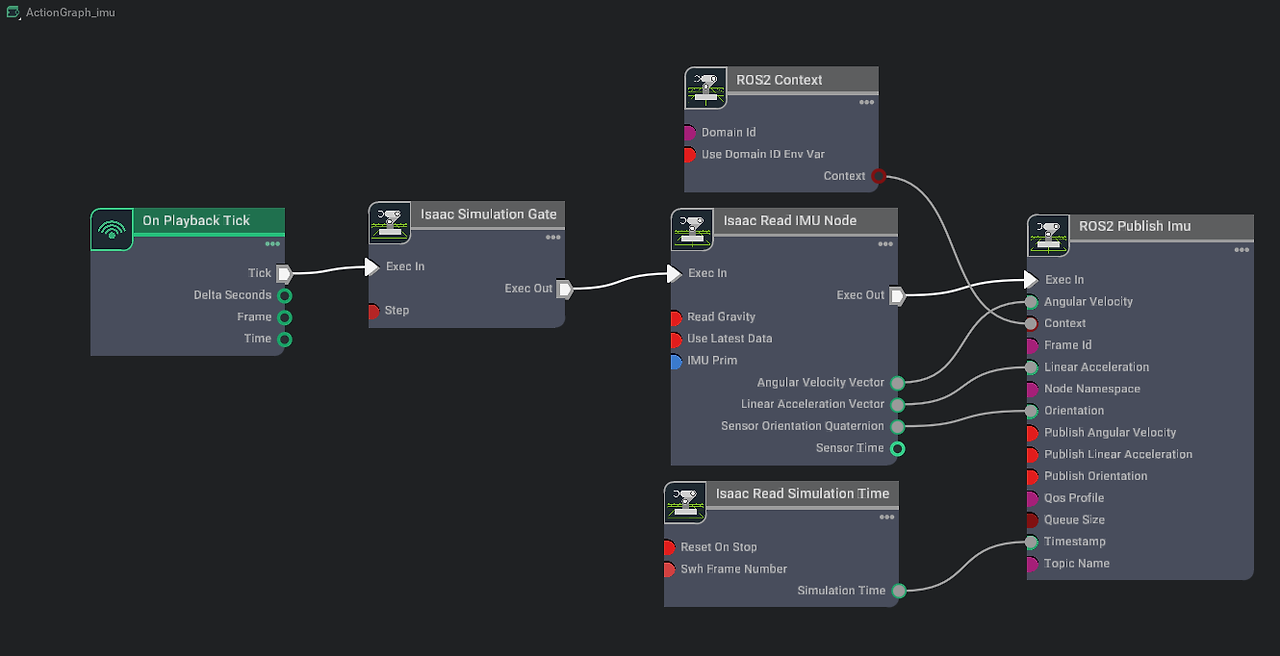
Isaac Sim ROS2 Tutorial 5: Publish Rate와 QoS 조정
Isaac Sim ROS2 OmniGraph에서 publish rate, frame skip, QoS profile, static publisher를 설정한다.
Read post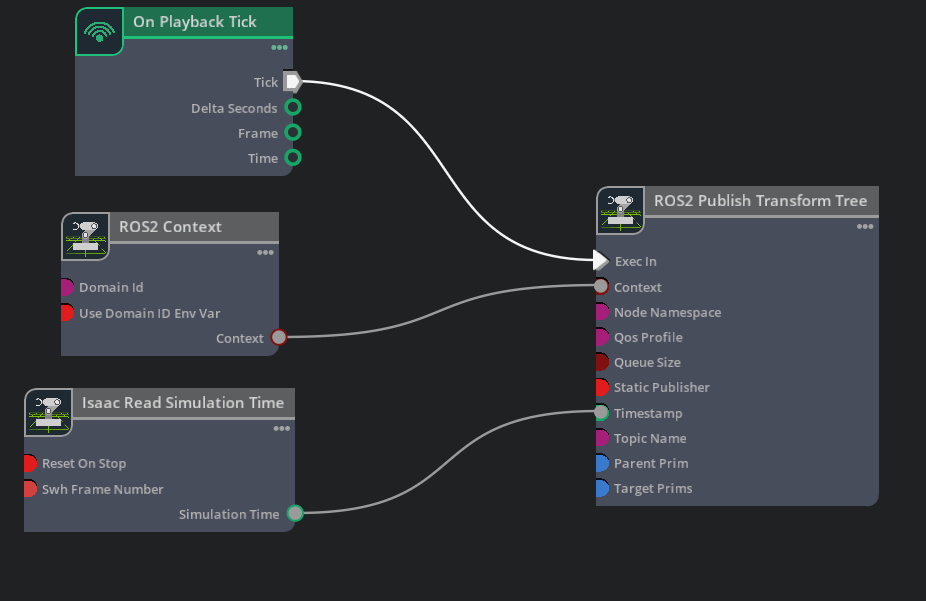
Isaac Sim ROS2 Tutorial 4: TF Tree와 Odometry 구성
TurtleBot의 sensor frame, odom frame, base frame을 ROS2 TF tree와 odometry topic으로 연결한다.
Read post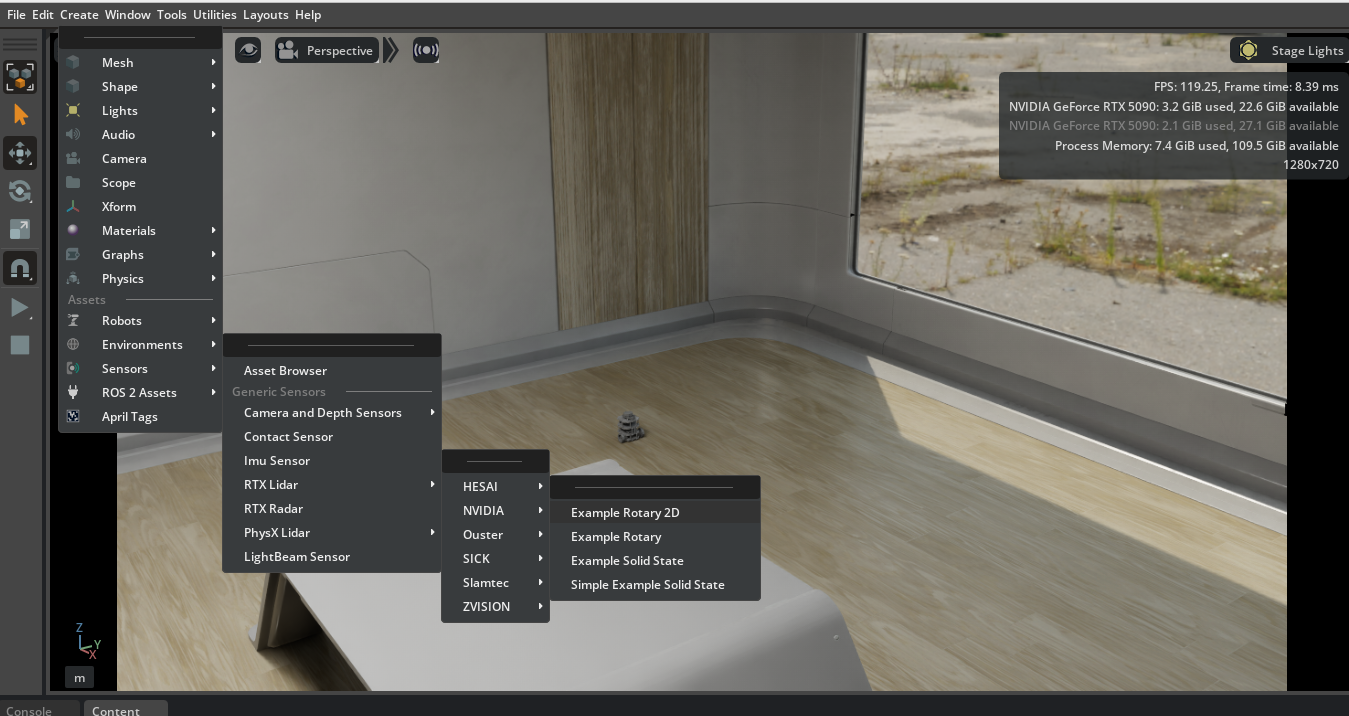
Isaac Sim ROS2 Tutorial 3: RTX Lidar Sensor 연결
TurtleBot에 RTX 2D/3D Lidar를 추가하고 LaserScan, PointCloud topic으로 publish한다.
Read post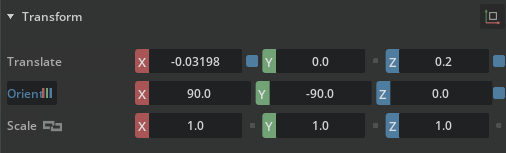
Isaac Sim ROS2 Tutorial 2: Camera Topic Publish
TurtleBot에 카메라를 추가하고 render product와 ROS2 Camera Helper로 image topic을 publish한다.
Read post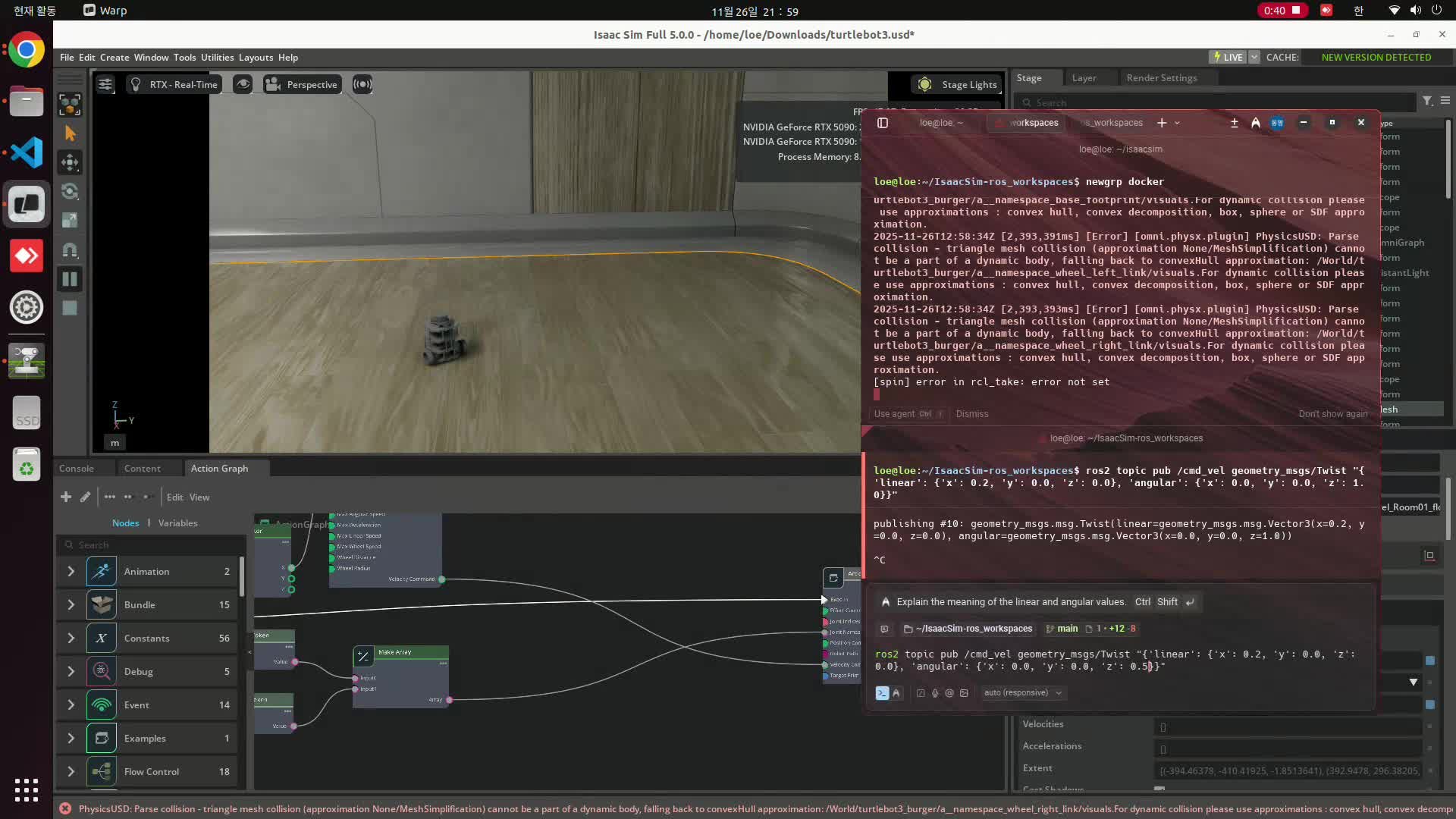
Isaac Sim ROS2 Tutorial 1: TurtleBot3 /cmd_vel 주행 연결
TurtleBot3 URDF를 Isaac Sim에 import하고 ROS2 /cmd_vel을 바퀴 joint velocity command로 연결한다.
Read post
6. Policy Gradient 계열 DRL 정리
DDPG, TRPO, Natural Policy Gradient, PPO가 정책 업데이트를 안정화하는 방식을 흐름 중심으로 정리한다.
Read post
5. Deep Reinforcement Learning 정리
DQN 계열과 Policy Gradient, REINFORCE, Actor-Critic, A3C, A2C의 핵심 아이디어를 연결해 정리한다.
Read post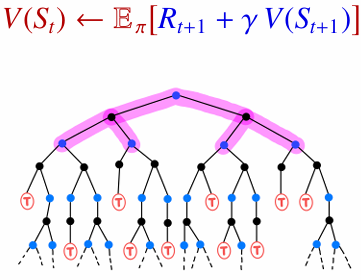
4. Model-Free Reinforcement Learning 정리
Unknown MDP에서 MC, TD, Sarsa, Q-Learning, Double Q-Learning이 가치를 추정하는 방식을 정리한다.
Read post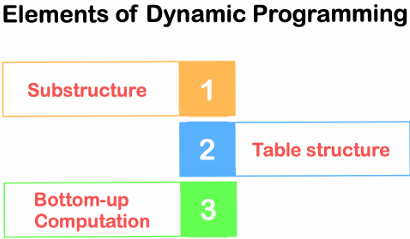
3. Dynamic Programming으로 Known MDP 풀기
환경 모델을 알고 있을 때 정책 반복과 가치 반복으로 최적 정책을 계산하는 과정을 정리한다.
Read post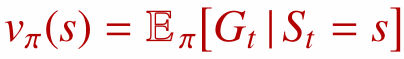
2. Bellman Equation과 가치 함수
가치 함수를 현재 보상과 다음 상태 가치의 관계로 표현하는 벨만 방정식의 의미를 정리한다.
Read post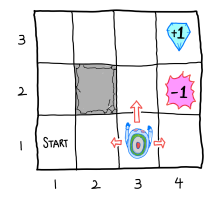
1. Markov Decision Process 기본 구조
강화학습 문제를 state, action, reward, transition probability, policy 관점에서 정리한다.
Read post